The Rise of Small Language Models (SLMs) vs. Large Language Models (LLMs)

Big models are impressive, but the future of many real-world AI systems looks “small-first.” SLMs (8B params and below, or highly distilled versions) are winning where latency, cost, privacy and local execution matter — and smart distillation + PEFT techniques are closing the gap on capability. Below I explain why, give practical tradeoffs, and list recent research you can read next (with notes on where those papers fall short).
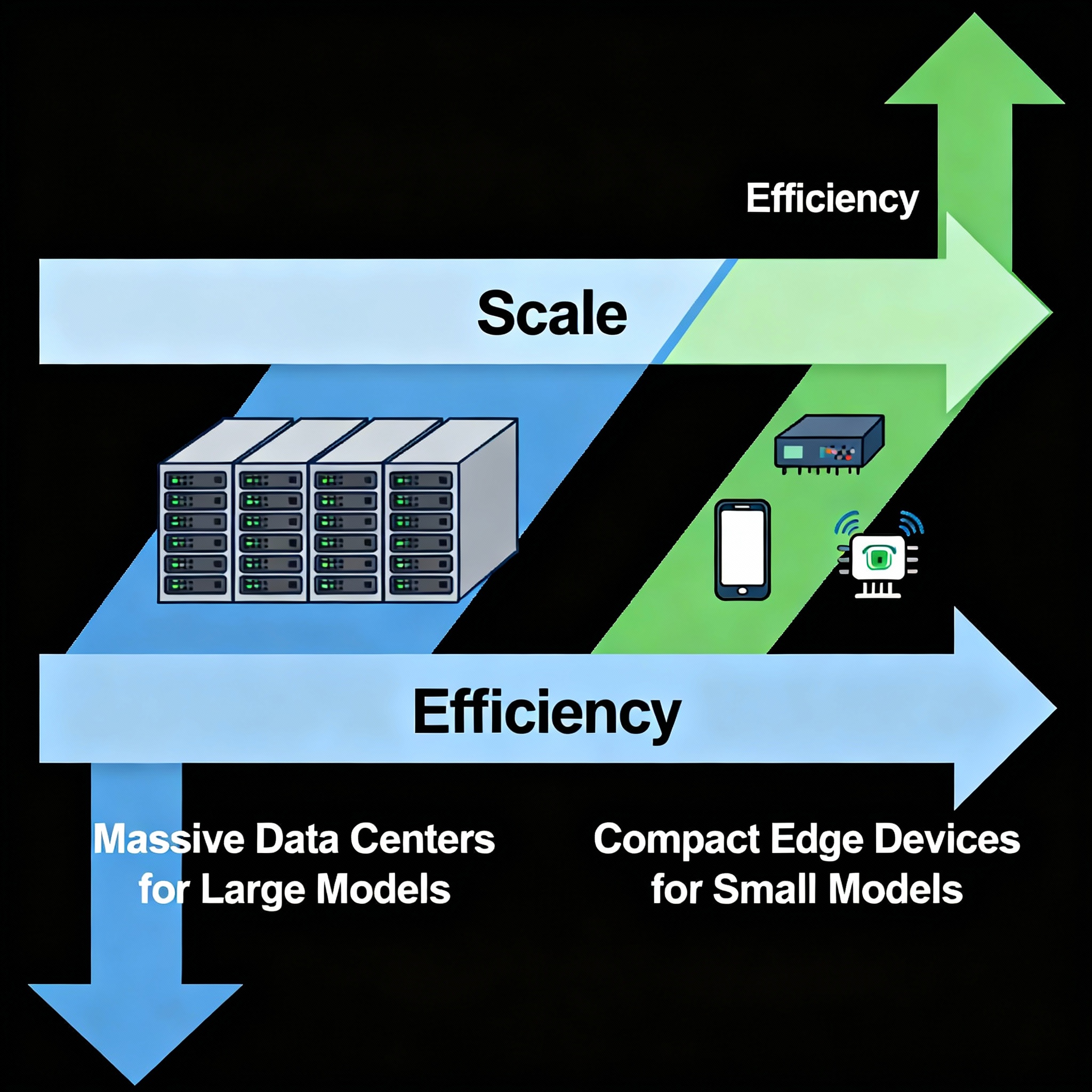
Over the past three years the AI conversation split into two camps: build ever-larger foundation models (billions–trillions of parameters) or optimize much smaller models for efficiency and deployability. LLMs deliver strong zero-shot and few-shot abilities, and they’re the headline-grabbers. But deploying them everywhere — on phones, IoT, edge servers, or in strict privacy settings — is expensive or impossible. That gap is why SLMs are rapidly gaining real-world interest.
What exactly is an SLM?
“Small Language Model” isn’t an exact size cutoff. In practice people use the term to mean compact base models (e.g., 7–8B) or aggressively distilled student models derived from much larger teachers. The defining traits are: low inference latency, small memory footprint, and ability to run on commodity hardware (or at least much smaller infrastructure than an LLM requires). Distillation and targeted architecture changes (e.g., weight sharing, quantization-friendly layers) are common tools to build SLMs.
Strengths of SLMs — where they beat LLMs today
Cost & latency — SLMs can run locally or on cheaper GPUs/CPUs, dramatically cutting inference costs and improving responsiveness for interactive applications (agents, mobile assistants). (Microsoft)
Privacy & control — local execution removes many data-sharing concerns; teams can audit, fine-tune, or freeze models without depending on cloud providers.
Modularity for agents — many agentic pipelines use tiny models for fast planning + a larger model only when needed; this “SLM-first” design scales better in production. Recent work argues SLMs are preferable for agent orchestration.
Energy & environmental footprint — smaller models consume less energy per query and reduce cloud compute demand.
Easier continual deployment — shipping incremental updates to compact models is operationally simpler and cheaper.
Where LLMs still hold the edge
Raw capability on complex, open-ended reasoning — larger models still have a lead on difficult reasoning, multi-step math, and wide-domain knowledge.
Generalization — LLMs trained at massive scale can generalize to tasks without task-specific tuning more reliably.
That gap is narrowing thanks to distillation and PEFT, but it’s not closed for every task.
How SLMs are catching up: techniques and practices
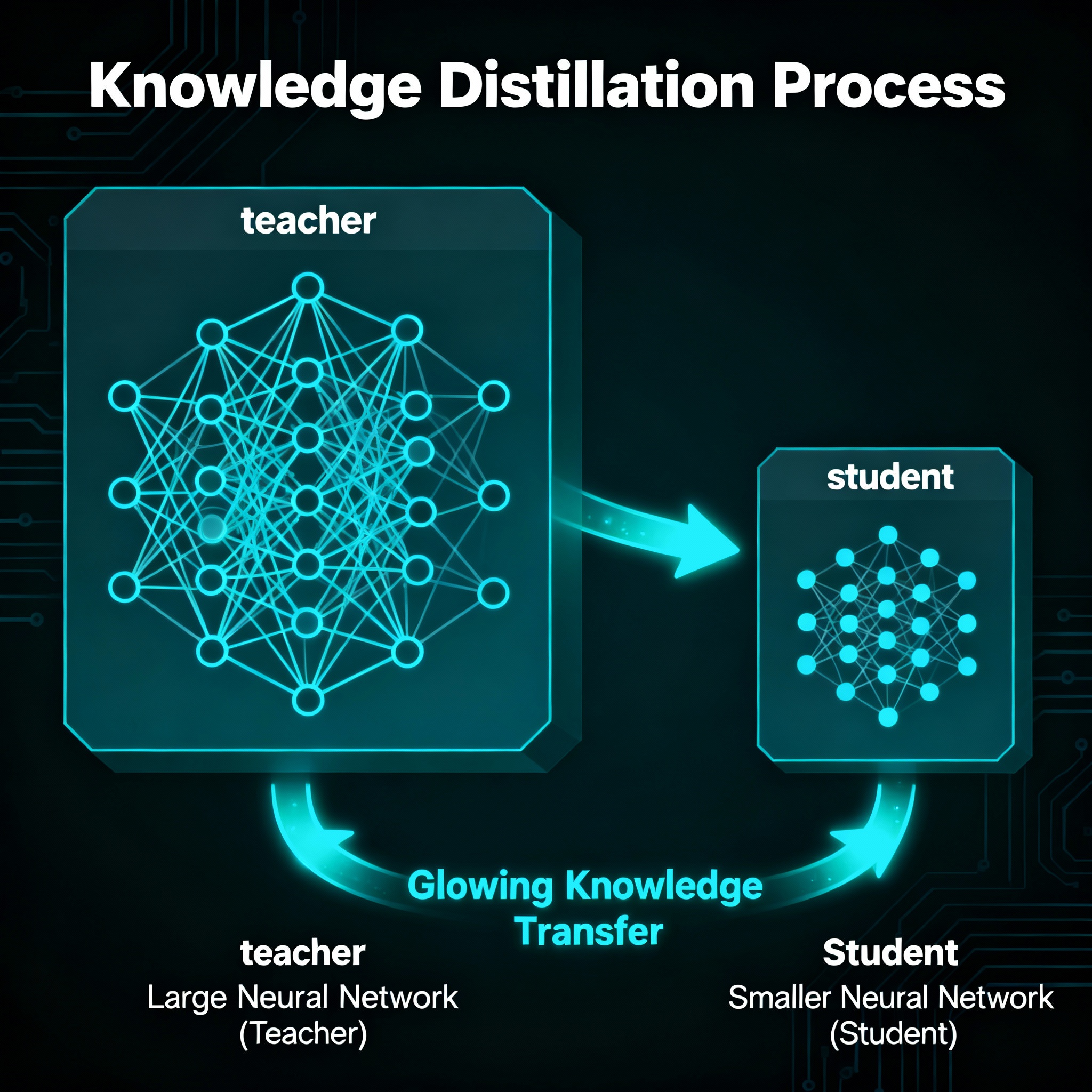
Knowledge distillation / TinyLLM approaches — teach a smaller model to reproduce not just outputs but also reasoning traces or intermediate logits from multiple large teachers (multi-teacher distillation). This improves student reasoning and robustness.
Parameter-Efficient Fine-Tuning (PEFT) — adapters, LoRA, prompt-tuning let you adapt a base SLM or LLM for specific tasks without full re-training, keeping resource use low. Surveys show PEFT is now a mature toolchain for efficient adaptation.
Quantization & compilation — lower-precision formats (8-bit, 4-bit) and optimized runtimes (llama.cpp-style toolchains, vendor compilers) let SLMs run on CPU or mobile with acceptable accuracy.
Hybrid architectures — use SLMs for front-line processing; call LLMs only for fallback or heavy-lift reasoning. This balances cost and capability and is common in agent design.
Practical guide: when to choose an SLM (quick checklist)
Need sub-second responses on-device → choose SLM.
Strict data privacy / regulatory constraints → SLM or on-prem LLM.
Limited budget for cloud compute → SLM+PEFT.
Requirement: best possible open-domain reasoning (research, complex synthesis) → LLM.
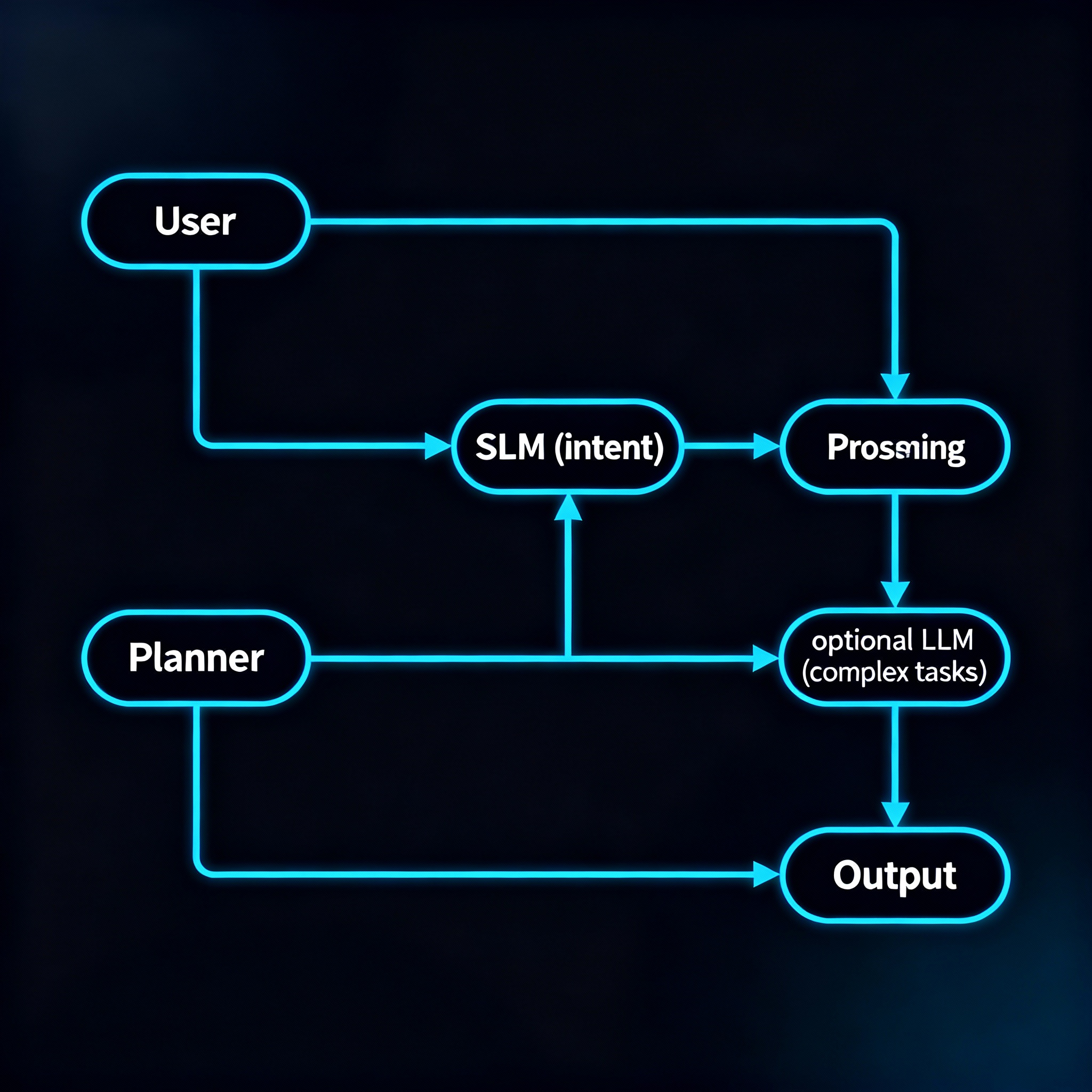
A short example architecture (SLM-first agent)
User input → SLM: intent + slot extraction, short context.
SLM → planner: generate step plan; if confident, execute via tools.
If plan requires complex reasoning or long-context summarization → call LLM.
Cache LLM answers; distill frequent patterns back into SLM periodically.
This pattern reduces calls to expensive LLMs while keeping UX snappy.
Business & industry lens
Several vendors and research teams now publish smaller models or optimized runtimes aimed at edge/enterprise use — the market is responding to demand for privacy, latency, and cost efficiency. Analysts suggest the SLM market will grow quickly as more companies adopt SLM-first strategies for agent and mobile AI products.
SLMs vs LLMs — A Clear Comparison
| Feature / Factor | SLMs (Small Language Models) | LLMs (Large Language Models) |
| Model Size | Typically under 8B parameters (or distilled versions) | 30B–1T+ parameters |
| Hardware Requirement | Runs on laptops, edge devices, or small servers | Needs high-end GPUs or large clusters |
| Latency | Fast responses (sub-second possible) | Higher latency, often cloud-dependent |
| Cost | Low inference cost, cheaper deployment | High operational cost |
| Privacy & Control | Can run fully on-premise or offline | Typically cloud-hosted; harder to fully control |
| Reasoning Power | Good on domain-specific or fine-tuned tasks | Superior general reasoning, zero-shot performance |
| Fine-Tuning Flexibility | Easy and cheap with PEFT | Expensive and resource-intensive |
| Energy Consumption | Lower, greener footprint | High energy usage |
| Best Use Cases | Mobile apps, on-device agents, cost-sensitive deployments | Research, complex reasoning, broad domain knowledge |
Risks & limits to watch
Misplaced optimism: Some claims that SLMs can replace LLMs across the board are premature; certain tasks still need scale. Independent benchmarking and red-teaming remain necessary.
Operational debt: managing many small models across clients can become complex; orchestration and monitoring tooling are required.
Security: fewer parameters doesn’t eliminate adversarial or data-poisoning risks.
A recent critical voice warns that relying solely on scale has diminishing returns — and that efficiency/algorithmic advances will be crucial — which strengthens the argument for SLMs but also reminds us to balance investments carefully.
Real-Life Case Studies
The growing adoption of Small Language Models isn’t just theoretical. Several industries have already integrated SLMs into production systems to reduce cost, increase speed, and ensure data privacy. Here are a few representative use cases:
1. On-Device AI Assistants in Consumer Electronics
Companies developing mobile devices and wearables have begun deploying SLMs to run voice and text-based assistants locally on hardware.
Why SLM: No internet requirement, fast responses, and better user data privacy.
Example: A smartphone assistant fine-tuned for offline translation and summarization tasks using an SLM runs smoothly on mid-range devices, avoiding reliance on large cloud-hosted models.
2. Financial Institutions and Privacy-Centric Chatbots
Banks and insurance companies are adopting SLMs for internal chatbots to assist employees with document queries, policy explanations, and report drafting.
Why SLM: Data security regulations make cloud hosting sensitive. On-prem SLMs ensure full control.
Example: A private bank deployed a 7B parameter distilled model behind its firewall, cutting down inference costs by 60% compared to using an external LLM API.
3. Edge Deployment in Industrial IoT
Manufacturing units are placing SLMs on edge servers to power predictive maintenance systems and sensor data interpretation.
Why SLM: Edge inference reduces latency and network dependency.
Example: An automotive plant uses an SLM to interpret machine logs locally and only escalates complex reasoning tasks to a larger cloud model.
4. Educational Platforms and Localized Learning Tools
EdTech companies are using SLMs for grammar correction, translation, and domain-specific tutoring in regional languages.
Why SLM: Faster, cheaper scaling and easy fine-tuning for local curriculum.
Example: A language learning app integrated a fine-tuned 3B SLM to support instant Kannada–English translation, replacing a costly external LLM API.
Research & further reading (selected papers + what needs work)
Below are a few recent, high-impact papers and articles — each entry includes a short note about where the work could be extended or improved.
“Small Language Models are the Future of Agentic AI” — Belcak et al., NVIDIA Research (2025).
Why read: Argues SLM-first architectures for agentic systems and provides empirical analysis.
Gaps / where to improve: more benchmarking on adversarial robustness and domain-shift; longer-term user studies to validate agent behavior in the wild.“Transferring Reasoning Capabilities to Smaller LLMs (TinyLLM)” — Tian et al., arXiv (2024).
Why read: Proposes multi-teacher distillation to transfer reasoning.
Gaps: scaling distillation to many domains; quantifying when distilled reasoning fails compared to teachers on safety-critical tasks.PEFT surveys (Wang et al., 2024–2025).
Why read: Comprehensive overview of adapters, LoRA, prompt-tuning as efficient adaptation strategies.
Gaps: more longitudinal studies on catastrophic forgetting and continual PEFT in production.Industry/analyst overviews (Meta Llama releases, HBR/Datacamp summaries).
Why read: Context on model sizes, public releases, and market trends.
Gaps: public releases rarely include full pretraining data details or energy accounting — independent audits would help.
Final thoughts — an actionable takeaway
If you’re building a product in 2025, don’t treat model size as a status symbol — treat it as a design parameter. Use SLMs where latency, cost, privacy and scale matter; reserve LLMs for complex fallback or research-heavy tasks. Invest in distillation pipelines, PEFT tooling, and reliable benchmarking. The most robust systems will likely be hybrid: small where possible, large where necessary.
Glossary of Key Terms
SLM (Small Language Model)
A compact language model (usually under 8B parameters) designed to run efficiently on lower-resource hardware. Commonly used for edge deployment, mobile applications, and cost-sensitive production systems.
LLM (Large Language Model)
A large-scale neural language model with tens of billions to trillions of parameters. Known for broad generalization and strong zero-shot reasoning capabilities, but requiring significant computational resources.
Distillation
A technique where a smaller “student” model learns to mimic the behavior of a larger “teacher” model, often improving performance without increasing size.
PEFT (Parameter-Efficient Fine-Tuning)
A set of methods (e.g., LoRA, adapters, prompt tuning) that fine-tune models without updating all their parameters, making adaptation cheaper and faster.
LoRA (Low-Rank Adaptation)
A PEFT method that injects trainable low-rank matrices into transformer layers, allowing efficient fine-tuning of models with minimal additional parameters.
Quantization
The process of converting a model’s weights to lower precision (e.g., 8-bit or 4-bit) to reduce memory usage and improve inference speed, often with minimal accuracy loss.
Edge Deployment
Running AI models directly on local devices or edge servers (instead of the cloud) to reduce latency, improve privacy, and save bandwidth.
Knowledge Distillation
A training approach where a smaller model is trained to replicate not only the outputs but also intermediate reasoning signals of a larger teacher model.
Hybrid Architecture
A system design pattern that combines SLMs and LLMs, using the smaller model for fast, common tasks and calling the larger model only for complex or rare cases.
Latency
The time delay between a user’s input and the model’s response. Lower latency improves interactivity, which is critical for real-time applications.
Zero-Shot / Few-Shot Learning
The ability of a model to solve tasks with no (zero-shot) or minimal (few-shot) task-specific training examples, often enabled by large-scale pretraining.
Continual Deployment
The practice of iteratively updating and rolling out model improvements without full retraining or system downtime, often easier with smaller models.
Privacy-Preserving Inference
Running models locally or in secure environments to prevent sensitive data from being exposed during model usage.
Energy Footprint
The total energy consumption associated with running or training a model. Smaller models usually have a lower footprint, making them more sustainable.
Agentic AI
AI systems designed to act autonomously or semi-autonomously by planning, reasoning, and executing tasks—often using a combination of SLMs and LLMs.